安装插件
1npm install hexo-math --save然后编辑站点根目录下的_config.yml,添加
|
|
3.修改你next模版下配置
vi themes/next/_config.yml12mathjax: enable: true
安装插件
|
|
然后编辑站点根目录下的_config.yml,添加
|
|
3.修改你next模版下配置
vi themes/next/_config.yml12mathjax: enable: true
|
|
 OpenGL PBO
OpenGL PBO
OpenGL ARB_pixel_buffer_object的扩展非常接近ARB_vertex_buffer_object。
它只是ARB_vertex_buffer_object的扩展,以便不仅存储顶点数据,而且像素数据到缓冲区对象。
存储像素数据的该缓冲对象称为像素缓冲对象(PBO)。
ARB_pixel_buffer_object扩展借用了所有VBO框架和API,另外,添加了2个额外的”target” tokens。
这些tokens辅助PBO存储器管理器(OpenGL驱动器)来确定缓冲器对象的最佳位置;
系统存储器,共享存储器或视频存储器。
此外,”target” tokens清楚地指定绑定的PBO将在两个不同操作中的一个中使用;
GL_PIXEL_PACK_BUFFER_ARB用于将像素数据传输到PBO,或GL_PIXEL_UNPACK_BUFFER_ARB用于从PBO传输像素数据。
例如,glReadPixels()和glGetTexImage()是“pack” 像素操作,glDrawPixels(),glTexImage2D()和glTexSubImage2D()是
“解包”操作。
当PBO与GL_PIXEL_PACK_BUFFER_ARB令牌绑定时,glReadPixels()从OpenGL帧缓冲区读取像素数据,并将数据写入(打包)到PBO中。
当PBO与GL_PIXEL_UNPACK_BUFFER_ARB令牌绑定时,glDrawPixels()从PBO读取(解压缩)像素数据并将其复制到OpenGL帧缓冲区。
PBO的主要优点是通过DMA(直接存储器访问)实现快速像素数据传输到图形卡和从图形卡传输,而不会影响CPU周期。
而且,PBO的另一个优点是异步DMA传输。
让我们比较一个传统的纹理传输方法和使用一个像素缓冲对象。
下图的左侧是从图像源(图像文件或视频流)加载纹理数据的常规方法。
源首先被加载到系统内存中,然后从系统内存复制到一个带有glTexImage2D()的OpenGL纹理对象。
这两个传送过程(加载和复制)都由CPU执行。
 无PBO的纹理加载
无PBO的纹理加载
 纹理加载与PBO
纹理加载与PBO
相反,在右侧图中,图像源可以直接加载到由OpenGL控制的PBO中。
CPU仍然涉及将源加载到PBO,但是不用于将像素数据从PBO传送到纹理对象。
相反,GPU(OpenGL驱动程序)管理将数据从PBO复制到纹理对象。
这意味着OpenGL执行DMA传输操作,而不会浪费CPU周期。
此外,OpenGL可以调度异步DMA传输以供稍后执行。
因此,glTexImage2D()立即返回,CPU可以执行其他操作,而不用等待像素传输完成。
有两个主要的PBO方法来提高像素数据传输的性能:
创建PBO
如前所述,Pixel Buffer Object从 顶点缓冲区对象中
借用所有API 。
唯一的区别是PBO有2个额外的token:
GL_PIXEL_PACK_BUFFER_ARB和GL_PIXEL_UNPACK_BUFFER_ARB。
GL_PIXEL_PACK_BUFFER_ARB用于将像素数据从OpenGL传输到应用程序,GL_PIXEL_UNPACK_BUFFER_ARB表示将像素数据从应用程序传输到OpenGL。
OpenGL指的是这些token以确定PBO的最佳存储空间,例如,用于上传(拆包)纹理的视频存储器或用于读取(打包)帧缓冲区的系统存储器。
然而,这些target token只是提示。
OpenGL驱动程序决定适当的位置。
创建PBO需要3个步骤:
使用glGenBuffersARB()生成一个新的缓冲区对象。
使用glBindBufferARB()绑定缓冲区对象。
使用glBufferDataARB()
将像素数据复制到缓冲区对象。
如果在glBufferDataARB()中指定了指向源数组的NULL指针,则PBO只分配给定数据大小的内存空间。
glBufferDataARB()的最后一个参数是PBO提供如何使用缓冲区对象的另一个性能提示。
GL_STREAM_DRAW_ARB用于流纹理上传,
GL_STREAM_READ_ARB用于异步帧缓冲读回。
请检查
VBO了解更多详情。
映射PBO
PBO提供了一种存储器映射机制,以将OpenGL控制的缓冲器对象映射到客户机的存储器地址空间。
因此,客户端可以通过使用
glMapBufferARB()和glUnmapBufferARB()
来修改缓冲区对象或整个缓冲区的一部分。
|
|
如果成功,glMapBufferARB()返回指向缓冲区对象的指针。
否则返回NULL。
该目标参数是GL_PIXEL_PACK_BUFFER_ARB或GL_PIXEL_UNPACK_BUFFER_ARB。
第二个参数,
access
指定如何处理映射缓冲区;
从PBO读取数据(GL_READ_ONLY_ARB),将数据写入PBO(GL_WRITE_ONLY_ARB)或两者(GL_READ_WRITE_ARB)。
注意,如果GPU仍然使用缓冲区对象,glMapBufferARB()将不会返回,直到GPU完成其作业与相应的缓冲区对象。
为了避免这种停顿(等待),在glMapBufferARB()之前调用带有NULL指针的glBufferDataARB()。
然后,OpenGL将丢弃旧的缓冲区,并为缓冲区对象分配新的内存空间。
缓冲区对象必须在使用PBO后通过glUnmapBufferARB()取消映射。
如果成功,glUnmapBufferARB()返回GL_TRUE。
否则,它返回GL_FALSE。
示例:流纹理上传
下载源码和二进制文件:
pboUnpack.zip(Updated:2014-04-24)
这个演示应用程序使用PBO上传(解压缩)流纹理到一个OpenGL纹理对象。
您可以通过按空格键切换到不同的传输模式(单个PBO,双PBO和无PBO),并比较性能差异。
在PBO模式中每个帧,纹理源直接写在映射的像素缓冲器上。
然后,使用glTexSubImage2D()将这些数据从PBO传输到纹理对象。
通过使用PBO,OpenGL可以在PBO和纹理对象之间执行异步DMA传输。
它显着增加了纹理上传性能。
如果支持异步DMA传输,glTexSubImage2D()应立即返回,并且CPU可以处理其他作业,而不等待实际的纹理复制。

要最大化流传输性能,您可以使用多个像素缓冲区对象。
该图显示了2个PBO同时使用;
当纹理源正在写入另一个PBO时,glTexSubImage2D()从PBO复制像素数据。
对于第n帧,
PBO 1
用于glTexSubImage2D(),
PBO 2
用于获取新的纹理源。
对于第n + 1帧,2个像素缓冲器正在切换角色并继续更新纹理。
由于异步DMA传输,更新和复制过程可以同时执行。
CPU将纹理源更新为PBO,而GPU从其他PBO复制纹理。
|
|
示例:异步读回
下载源码和二进制文件:
pboPack.zip(Updated:2014-05-13)。
此演示应用程序将帧缓冲区(左侧)的像素数据读取(打包)到PBO,然后在修改图像的亮度之后将其绘制回窗口的右侧。
您可以通过按空格键切换PBO开/关,并测量glReadPixels()的性能。
传统的glReadPixels()阻塞流水线并等待,直到所有像素数据被传输。
然后,它将控制权返回给应用程序。
相反,具有PBO的glReadPixels()可以调度异步DMA传输并立即返回而不会停顿。
因此,应用程序(CPU)可以立即执行其他进程,同时通过OpenGL(GPU)使用DMA传输数据。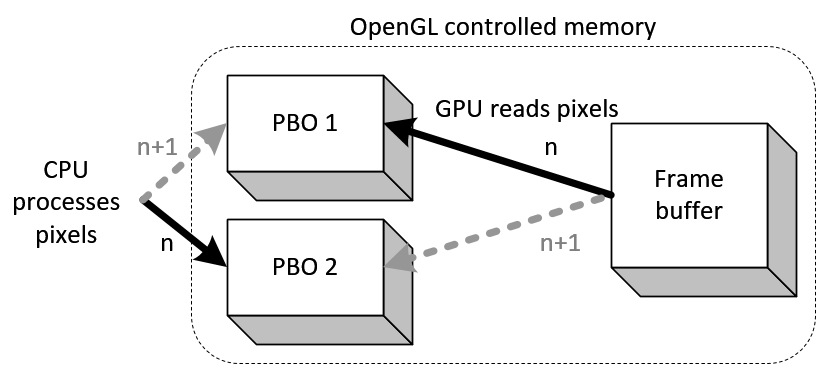
应用程序使用glReadPixels()从OpenGL帧
缓冲区读取像素数据到PBO 1,并处理PBO 2中的像素数据.
这些读取和处理可以同时执行,因为glReadPixels()到PBO 1立即返回,并且CPU开始在PBO 2中无延迟地处理数据。
并且,我们在每个帧上
在PBO 1和PBO 2之间交替
|
|
群里的基友大牙,前几天写了一个延迟的总结:相关链接
基于项目本身的实际情况考虑,我还是保留了缓冲区。
|
|
|
|
在有缓冲区的前提下,我的想法是:
问题1: 丢帧的阀值和缓冲区的大小都是3秒,会不会造成刚缓冲完就丢了呢?
:不会!
代码分析:暂停的触发条件是没有数据了,会把paused置成1.
|
|
ffp_check_buffering_l这个的函数的作用是: 查看下可否把paused置成0.
也就是说,不管你缓冲区多大,只有消耗掉所有数据才会暂停,然后开始攒数据,达到缓冲区的时候恢复播放。
只能说缓冲区设置的越小,在流不稳定的情况下,卡顿次数会更多一些。
:平稳的流可以不要缓冲区,如果推流端不稳定,建议还是保持1-3秒缓冲。
看下ffp_check_buffering_l()
|
|
原生的是
|
|
原生的不好之处在于,判断size和时间,取最大值,这种方式作为SDK没关系,但最直播而言,不太合适
|
|
看定义知道:缓冲区size是256K,time的话是阶梯式的:开始是100ms,然后1s,2s,3s,4s,5s,阶梯上升;
我建议直播最大阀值改成3s可能更好。
|
|
再看下,time的缓冲池是用的音频的呢,还是视频的呢?
|
|
原来又是用的最小值
换算成百分比就是
|
|
实际上,有些流的video_cached_duration是0,因为流各有差异。
所以一般是用音频的时间作为缓冲buf,基本上size的buffer可以弃用,因为帧率和码率的缘故,size基本不准。
回到问题1,为什么暂停的时候不建议丢帧,因为会造成你刚攒够了数据,达到播放条件的时候,又达到了丢帧的max_cached_duration(我设置的是3s),你说是不是很杯具啊? 就是你刚领完工资就花没了,是不是感觉人生没有盼望啊?
正所谓:患难生忍耐,忍耐生老练,老练生盼望……(罗马书5:8)
所以说如果你暂停也触发丢帧的话,你可能会卡住比较长的时间,影响体验。
这样改完,基本上就OK了,但还有个不好的体验,就是当主播网络抖动或者别的网络异常时,音频丢帧后,视频会加速播;
我参考别的平台,比如映客和咸蛋家,他们这块做的不错,画面不是加速的,而是切画面。
我思前想后,觉得只能采取两种方式做:
重连其实可以不用考虑,因为重连的触发最好是抛ERROR,也可以在COMPELETED的时候重连,但要看具体情况。
你正常的时候重连,这是闹哪样?
我看映客的做法是这样,因为他们是双路流,音视频不同步大概3秒左右,就会重连一下,双路流要处理的逻辑很复杂,估计映客已经切回单路了。
如果你的主播糟糕的网络持续了很长一段时间(限速上行50KB/S 1-2分钟),播放端肯定就音画不同步,而且短时间很难恢复,这时候如果丢音频帧,追视频帧(画面加速),可能半天才恢复到当前,其实这时候最好是重连一下,免得用户等的久(但这种情况在实际场景中少见,等久一点问题也不大)
言归正传,想想怎么跳帧渲染吧
先分析这个函数: 用于显示每帧画面的
|
|
这样我就可以在显示的时候丢帧了,但是其实并不是这样,因为ijk定义的视频帧队列最大只有3个frame,
|
|
如果你用默认值,你一次只能丢两个frame,即使你改成VIDEO_PICTURE_QUEUE_SIZE_MAX,也不过丢16个帧,1s左右
其实也不能满足我跳帧的需求
我增加一个清除frame接口
|
|
如果我把f->max_size 设置的无比大,比如30,60,那么读到的包会源源不断的来解码,然后显示,这样会不会有问题呢?
f->max_size 超过16会有问题。
跳帧渲染貌似暂时行不通,那还是先丢解码前的视频包吧;
搭建Mac+hexo环境参考文章:
Mac搭建hexo博客
修改配置参考hexo的中文官网:
hexo的中文官网
常见的设置有:
|
|
|
|
|
|
这都是显示在侧边栏的,当然也可以修改侧边栏的属性, 比如放在左边,是否隐藏等。
Note: 每次修改的时候,key: value, 中间都要一个空格!
新建的md文件的时候记得添加标题格式:
title: Hello World
部署:123456cd source/_posts/vi 1.mdhexo chexo ghexo d
遇到的坑:
Error: fatal: Not a git repository (or any of the parent directories): .git
解决:
把.deploy_git文件夹手动删除了,
rm -rf .deploy_git
重新hexo deploy了一次,成功!